减少前端代码耦合
什么是代码耦合?代码耦合的表现是改了一点毛发而牵动了全身,或者是想要改点东西,需要在一堆代码里面找半天。由于前端需要组织js/css/html,耦合的问题可能会更加明显,下面按照耦合的情况分别说明:
1. 避免全局耦合
这应该是比较常见的耦合。全局耦合就是几个类、模块共用了全局变量或者全局数据结构,特别是一个变量跨了几个文件。例如下面,在html里面定义了一个变量:
1 | <script> |
上面在head标签里面定义了一个PAGE的全局变量,然后在main.js里面使用。这样子PAGE就是一个全局变量,并且跨了两个文件,一个html,一个js。然后在main.js里面突然冒出来了个PAGE的变量,后续维护这个代码的人看到这个变量到处找不到它的定义,最后找了半天发现原来是在xxx.html的head标签里面定义了。这样就有点egg pain了,并且这样的变量容易和本地的变量发生命名冲突。
所以如果需要把数据写在页面上的话,一个改进的办法是在页面写一个form,数据写成form里面的控件数据,如下:
1 | <form id="page-data"> |
上面使用了input和textarea,使用textarea的优点是支持特殊符号。再把form的数据序列化,序列化也是比较简单的,可以查看 Effective前端2:优化html标签
第二种是全局数据结构,这种可能会使用模块化的方法,如下:
1 | //data.js |
上面四个模块各司其职,乍一眼看上去好像没什么问题,但是他们都用了一个data的模块共用数据。这样确实很方便,但是这样就全局耦合了。因为用的同一个data,所以你无法保证,其它人也会加载了这个模块然后做了些修改,或者是在你的某一个业务的异步回调也改了这个。第二个问题:你不知道这个data是从哪里来的,谁可能会对它做了修改,这个过程对于后续的模块来说都是不透明的。
所以这种应该考虑使用传参的方式,降低耦合度,把data作为一个参数传递:
1 | //去掉data.js |
可以看到,search里面获取到data后,交给format-data处理,format-data处理完之后再给show-result。这样子就很清楚地知道数据的处理流程,并且保证了houseList不会被某个异步回调不小心改了。如果单独从某个模块来说,show-result这个模块并不需要关心houseList的经过了哪些流程和处理,它只需要关心输入是符合它的格式要求的就可以。
这个时候你可能会有一个问题:这个data被逐层传递了这么多次,还不如像最上面的那样写一个data的模块,大家都去改那里,岂不是简单了很多?对,这样是简单了,但是一个数据结构被跨了几个文件使用,这样会出现我上面说的问题。有时候可能出现一些意想不到的情况,到时候可能得找bug找个半天。所以这种解耦是值得的,除非你定义的变量并不会跨文件,它的作用域只在它所在的文件,这样会好很多。或者是data是常量的,data里面的数据定义好之后值就再也不会改变,这样应当也是可取的。
2. js/css/html的耦合
这种耦合在前端里面应该最常见,因为这三者通常具有交集,需要使用js控制样式和html结构。如果使用js控制样式,很多人都喜欢在js里面写样式,例如当页面滑动到某个地方之后要把某个条吸顶:

页面滑到下面那个灰色的条再继续往下滑的时候,那个灰色条就要保持吸顶状态:

可能不少人会这么写:
1 | $(".bar").css({ |
然后当用户往上滑的时候取消fixed:
1 | $(".bar").css({ |
如果你用react,你可能会设置一个style的state数据,但其实这都一样,都把css杂合到js里面了。某个想要检查你样式的人,想要给你改个bug,他检查浏览器发现有个标签style里的属性,然后他找半天找不到是在哪里设置的,最后他发现是在某个js的某个隐蔽的角落设置了。你在js里面设置了样式,然后css里面也会有样式,在改css的时候,如果不知道js里面也有设置了样式,那么可能会发生冲突,在某种条件下触发了js里面设置样式。
所以不推荐直接在js里面更改样式属性,而应该通过增删类来控制样式,这样子样式还是回归到css文件里面。例如上面可以改成这样:
1 | //增加fixed |
fixed的样式:
1 | .bar.fixed{ |
可以看到,这样的逻辑就非常清晰,并且回滚fixed,不需要把它的position还原为static,因为它不一定是static,也有可能是relative,这种方式在取消掉一个类的时候,不需要去关心原本是什么,该是什么就会是什么。
但是有一种是避免不了的,就是监听scroll事件或者mousemove事件,动态地改变位置。
这种通过控制类的方式还有一个好处,就是当你给容器动态地增删一个类时,你可以借助子元素选择器,用这个类控制它的子元素的样式,也是很方便。
还有很多人可能会觉得html和css/js脱耦,那就是不能在html里面写style,不能在html里面写script标签,但是凡事都不是绝对的,如果有一个标签,它和其它标签就一个font-size不一样,那你直接给它写一个font-size的内联样式,又何尝不可呢,在性能上来说,如果你写个class,它还得去匹配这个class,比不上style高效吧。或者是你这个html文件就那么20、30行css,那直接在head标签加个style,直接写在head里面好了,这样你就少管理了一个文件,并且浏览器不用去加载一个外链的文件。
有时候直接在html写script标签是必要的,它的优势也是不用加载外链文件,处理速度会很快,几乎和dom渲染同时,这个在解决页面闪动的时候比较有用。因为如果要用js动态地改变已经加载好的dom,放在外链里面肯定会闪一下,而直接写的script就不会有这个问题,即使这个script是放在了body的后面。例如下面:
原始数据是带p标签的,但是在textarea里面展示的时候需要把p改成换行\r\n,如果在dom渲染之后再在外链里面更新dom就会出现上面的闪动的情况。你可能会说我用react,数据都是动态渲染的,渲染前已经处理好了,不会出现上面的情况。那么,好吧,至少你了解一下吧。
和耦合相对的是内聚,写代码的原则就是低耦合、高聚合。所谓内聚就是说一个模块的职责功能十分紧密,不可分割,这个模块就是高内聚的。我们先从重复代码说起:
3. 减少重复代码
假设有一段代码在另外一个地方也要被用到,但又不太一样,那么最简单的方法当然是copy一下,然后改一改。这也是不少人采取的办法,这样就导致了:如果以后要改一个相同的地方就得同时改好多个地方,就很麻烦了。
例如有一个搜索的界面:

用户可以通过点击search按钮触发搜索,也可以通过点击下拉或者通过输入框的change触发搜索,所以你可能会这么写:
1 | $("#search").on("click", function(){ |
在change里面又重新发请求:
1 | $("input").on("change", function(){ |
change里面需要对搜索条件的展示进行更改,和click事件不太一样,所以图一时之快就把代码拷了一下。但是这样是不利于代码的维护的,所以你可能会想到把获取数据和发请求的那部分代码单独抽离封装在一个函数,然后两边都调一下:
1 | function getAndShowData(){ |
在抽成一个函数的基础上,又发现这个函数其实有点大,因为这里面要获取表单数据,还要对数据进行格式化,用做请求的参数。如果用户触发得比较快,还要记录上次请求的xhr,在每次发请求前cancle掉上一次的xhr,并且可能对请求做一个loading效果,增加用户体验,还要对出错的情况进行处理,全部都要在ajax里面。所以最好对getAndShowData继续拆分,很自然地会想到把它分离成一个模块,一个单独的文件,叫做search-ajax。所有发请求的处理都在这个模块里面统一操作。对外只提供一个search.ajax的接口,传的参数为当前的页数即可。所有需要发请求的都调一下这个模块的这个接口就好了,除了上面的两种情况,还有点击分页的情景。这样不管哪种情景都很方便,我不需要关心请求是怎么发的,结果是怎么处理的,我只要传一个当前的页数给你就好了。
再往下,会发现,在显示结果那里,即上面代码的第7行,需要对有结果、无结果的情况分别处理,所以又搞了一个函数叫做showResult,这个函数有点大,它里面的逻辑也比较复杂,有结果的时候除了更新列表结果,还要更新结果总数、更新分页的状态。因此这个showResult一个函数难以担当大任。所以把这个show-result也当独分离出一个模块,负责结果的处理。
到此,我们整一个search的UML图应该是这样的:
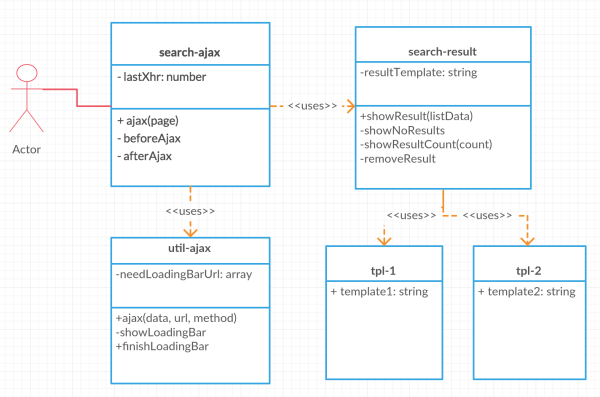
注意上面把发请求的又再单独封装成了一个模块,因为这个除了搜索发请求外,其它的请求也可以用到。同时search-result会用到两个展示的模板。
由于不只一个页面会用到搜索的功能,所以再把上面继续抽象,把它封装成一个search-app的模块,需要用到的页面只需require这个search-app,调一下它的init函数,然后传些定制的参数就可以用了。这个search-app就相当于一个搜索的插件。
所以整一个的思路是这样的:出现了重复代码 -> 封装成一个函数 -> 封装成一个模块 -> 封装成一个插件,抽象级别不断提高,将共有的特性和有差异的地方分离出来。当你走在抽象与封装的路上的时候,那你应该也是走在了大神的路上。
当然,如果两个东西并没有共同点,但是你硬是要搞在一起,那是不可取的。
我这里说的封装并不是说,你一定要使用requirejs、es6的import或者是webpack的require,关键在于你要有这种模块化的思想,并不是指工具上的,不管你用的哪一个,只要你有这种抽象的想法,那都是可取的。
模块化的极端是拆分粒度太细,一个简单的功能,明明十行代码写在一起就可以搞定的事情,硬是写了七、八层函数栈,每个函数只有两、三行。这样除了把你的逻辑搞得太复杂之外,并没有太多的好处。当你出现了重复代码,或者是一个函数太大、功能太多,又或是逻辑里面写了三层循环又再嵌套了三层if,再或是你预感到你写的这个东西其他人也可能会用到,这个时候你才考虑模块化,进行拆分比较合适。
上面不管是search-result还是search-ajax他们在功能上都是高度内聚的,每个模块都有自己的职责,不可拆分,这在面向对象编程里面叫做单一责职原则,一个模块只负责一个功能。
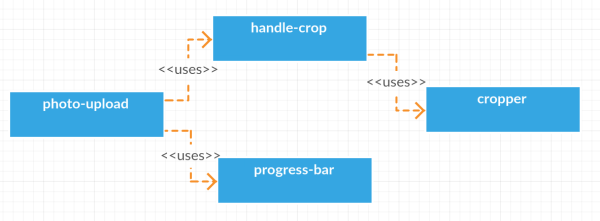
再举一个例子,我在怎样实现前端裁剪上传图片功能里面提到一个上传裁剪的实现,这里面包含裁剪、压缩上传、进度条三大功能,所以我把它拆成三个模块:
这里提到的模块大部分是一个单例的object,不会去实例它,一般可以满足大部分的需求。在这个单例的模块里面,它自己的“私有”函数一般是通过传参调用,但是如果需要传递的数据比较多的时候,就有点麻烦了,这个时候可以考虑把它封装成一个类。
4. 封装成一个类
在上面的裁剪上传里面的进度条progress-bar,一个页面里可能有几个要上传的地方,每个上传的地方都会有进度条,每个进度条都有自己的数据,所以不能像在最上面说的,在一个文件的最上面定义一些变量然后为这个模块里面的函数共用,只能是通过传递参数的形式,即在最开始调用的时候定义一些数据,然后一层一层地传递下去。如果这些数据很多的话就有点麻烦。
所以稍微变通一下,把progress-bar封装成一个类:
1 | function ProgressBar($container){ |
或者你用ES6的class,但是本质上是一样的,然后这个ProgressBar的成员函数就可以使用定义的这些“私有”变量,例如设置进度条的进度函数:
1 | ProgressBar.prototype.setProgress = function(percentage, time){ |
这个使用了两个私有变量,如果再加上原先两个,用传参的方式就得传四个。
使用类是模块化的一种思想,另外一种常用的还有策略模式。
5. 使用策略模式
假设要实现下面三个弹框:
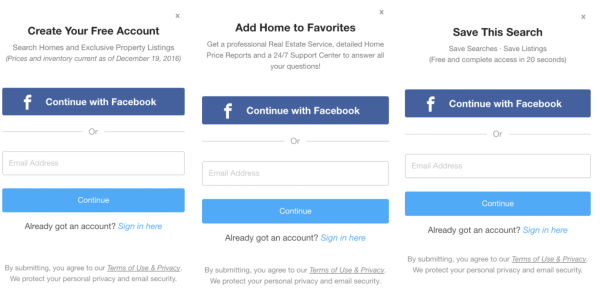
这三个弹框无论是在样式上还是在功能上都是一样的,唯一的区别是上面标题文案是不一样的。最简单的可能是把每个弹框的html都copy一下,然后改一改。如果你用react,你可能会用拆分组件的方式,上面一个组件,下面一个组件,那么好吧,你就这样搞吧。如果你没用react,你可能得想办法组织下你的代码。
如果你有策略模式的思想,你可能会想到把上面的标题当作一个个的策略。首先定义不同弹框的类型,一一标志不同的弹框:
1 | var popType = ["register", "favHouse", "saveSearch"]; |
定义三种popType一一对应上面的三个弹框,然后每种popType都有对应的文案:
1 | Data.text.pop = { |
{tittle: “”, subtitle: “”}这个就当作是弹框文案策略,然后再写弹框的html模板的时候引入一个占位变量:
1 | <section> |
在渲染这个弹框的时候,根据传进来的popType映射到不同的文案:
1 | function showPop(popType){ |
这里用Data.text.pop[popType]映射到了对应的文案,如果用react你把一个个的标题封装成一个组件,其实思想是一样的。
但是这个并不是严格的策略模式,因为策略就是要有执行的东西嘛,我们这里其实是一个写死的文案,但是我们借助了策略模式的思想。接下来继续说使用策略模式做一些执行的事情。
在上面的弹框的触发机制分别是:用户点击了注册、点击了收藏房源、点击了保存搜索条件。如果用户没有登陆就会弹一个注册框,当用户注册完之后,要继续执行用户原本的操作,例如该收藏还是收藏,所以必须要有一个注册后的回调,并且这个回调做的事情还不一样。
当然,你可以在回调里面写很多的if else或者是case:
1 | function popCallback(popType){ |
但是当你的case很多的时候,看起来可能就不是特别好了,特别是if else的那种写法。这个时候就可以使用策略模式,每个回调都是一个策略:
1 | var popCallback = { |
然后根据popType映射调用相应的callback,如下:
1 | var popCallback = require("pop-callback"); |
这样它就是一个完整的策略模式了,这样写有很多好处。如果以后需要增加一个弹框类型popType,那么只要在popCallback里面添加一个函数就好了,或者要删掉一个popType,相应地注释掉某个函数即可。并不需要去改动原有代码的逻辑,而采用if else的方式就得去修改原有代码的逻辑,所以这样对扩展是开放的,而对修改是封闭的,这就是面向对象编程里面的开闭原则。
在js里面实现策略模式或者是其它设计模式都是很自然的方式,因为js里面function可以直接作为一个普通的变量,而在C++/Java里面需要用一些技巧,玩一些OO的把戏才能实现。例如上面的策略模式,在Java里面需要先写一个接口类,里面定义一个接口函数,然后每个策略都封装成一个类,分别实现接口类的接口函数。而在js里面的设计模式往往几行代码就写出来,这可能也是做为函数式编程的一个优点。
前端和设计模式经常打交道的还有访问者模式
5. 访问者模式
事件监听就是一个访问者模式,一个典型的访问者模式可以这么实现,首先定义一个Input的类,初始化它的访问者列表
1 | function Input(inputDOM){ |
然后提供一个对外的添加访问者的接口:
1 | Input.prototype.on = function(eventType, callback){ |
使用者调用on,传递两个参数, 一个是事件类型,即访问类型,另外一个是具体的访问者,这里是回调函数。Input就会将访问者添加到它的访问者列表。
同时Input还提供了一个删除访问者的接口:
1 | Input.prototype.off = function(eventType, callback){ |
这样子,Input就和访问者建立起了关系,或者说访问者已经成功地向接收者都订阅了消息,一旦接书者收到了消息会向它的访问者一一传递:
1 | Input.prototype.trigger = function(eventType, event){ |
trigger可能是用户调的,也可能是底层的控件调用的。在其它领域,它可能是一个光感控件触发的。不管怎样,一旦有人触发了trigger,接收者就会一一下发消息。
如果你知道了事件监听的模式是这样的,可能对你写代码会有帮助。例如点击下面的搜索条件的X,要把上面的搜索框清空,同时还要触发搜索,并把输入框右边的X去掉。要附带着做几件事情。
这个时候你可能会这样写:
1 | $(".icon-close").on("click", function(){ |
但其实这样有点累赘,因为在上面的搜索输入框肯定也会相应的操作,当用户输入为空时,自动隐藏右边的x,并且输入框change的时候会自动搜索,也就是说所有附加的事情输入框那边已经有了,所以其实只需要触发下输入框的change事件就好了:
1 | $(".icon-close").on("click", function(){ |
输入框为空时,该怎么处理,search输入框会相应地处理,下面那个条件展示的x不需要去关心。触发了change之后,会把相应的消息下发给search输入框的访问者们。
当然,你用react你可能不会这样想了,你应该是在研究组件间怎么通信地好。
上文提及使用传参避免全局耦合,然后在js里面通过控制class减少和css的耦合,和耦合相对的是内聚,出发点是重复代码,减少拷贝代码会有一个抽象和封装的过程:function -> 模块 -> 插件/框架,封装常用的还有封装成一个类,方便控制私有数据。这样可实现高内聚,除此方法,还有设计模式的思想,上面介绍了策略模式和访问者模式的原理和应用,以及在写代码的启示。
希望上文能对你有所启迪,如有不对之处还请指出。
扩展阅读: